В ТувГУ продолжаются научные дискуссии по проблемам компьютерной обработки тюркских языков
Во второй день IХ-ой Международной конференции по компьютерной обработке тюркских языков с докладами на секциях «Корпусные технологии», «Тюркские википедии» выступили ученые из Университета Южной Флориды, Национального университета Узбекистана им. Мирзо Улугбека, Бухарского государственного университета, Ташкентского государственного университета языка и литературы им. Алишера Навои, Института прикладной семиотики АН РТ, Института филологии СО РАН, Центра развития традиционной тувинской культуры и ремесел, Института истории, языка и литературы УФИЦ РАН, Горно-Алтайского государственного университета, Томского государственного педагогического университета, Хакасского государственного университета, Тувинского государственного университета.
Доклады ученых были посвящены актуальным вопросам создания и развития национальных корпусов и баз данных, разметке и редактированию параллельных корпусов, созданию электронных ресурсов на тюркских языках. Впервые в истории конференции была организована секция «Тюркские википедии», в работе которой приняли участие известные википедисты, волонтеры международного движения Викимедиа. На данной секции большой интерес вызвал доклад Али Кужугета, представленный на тувинском языке и посвященный вкладу википедистов в «Тыва Википедии» во время пандемии коронавируса.
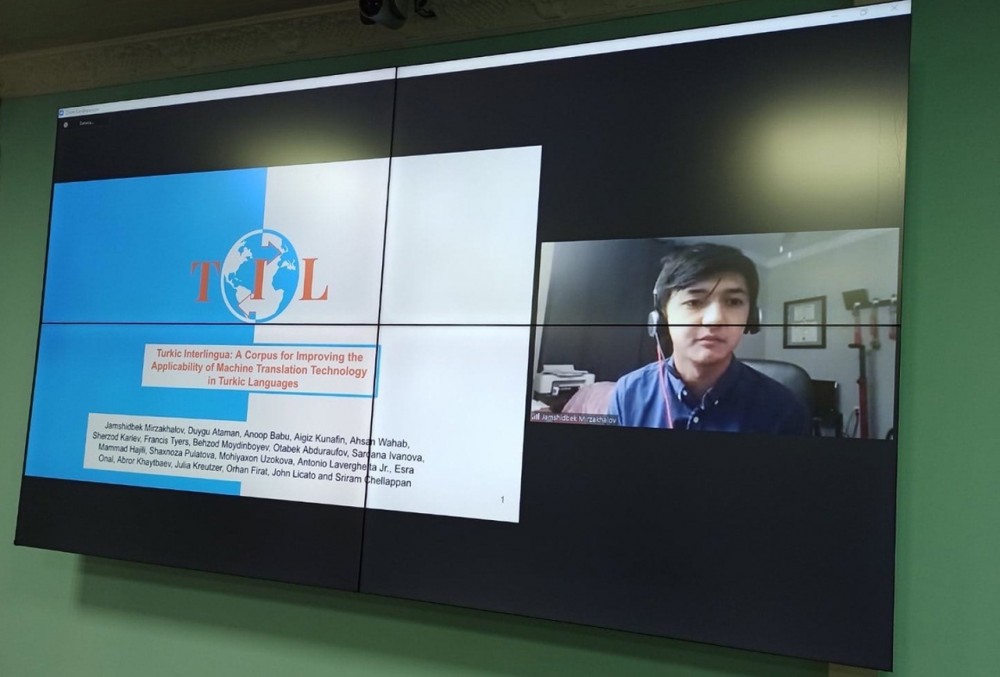
Фото - tuvsu.ru
Участниками секции «Корпусные технологии» стали преподаватели Тувинского госуниверситета - доцент кафедры тувинской филологии и общего языкознания Аэлита Салчак, доцент кафедры русского языка и литературы Валентина Ондар с докладом «Русско-тувинские параллельные тексты как база создания параллельного подкорпуса Электронного корпуса тувинского языка и основа для научных исследований». Работа посвящена первым итогам создания параллельного подкорпуса Электронного корпуса текстов тувинского языка.
Проблеме эквивалентности параллельных предложений в текстовом корпусе для русско-татарского переводчика было посвящено выступление других участников секции - сотрудников Института прикладной семиотики АН Республики Татарстан Булата Хакимова и Марата Шаеховича. С докладом «Создание базы данны
х текстов, написанных на латинской графике» выступила старший научный сотрудник НОЦ «Тюркология» Аржаана Хертек. Выступление аспирантки ТувГУ Чыжырганы Саая было посвящено базе данных периодической печати начала 20 в. на тувинском языке. Речь шла о необходимости оцифровки редких сохранившихся экземпляров газет на тувинском языке. О состоянии и проблемах Электронного корпуса текстов алтайского языка рассказала в своем докладе декан факультета алтаистики и тюркологии Горно-Алтайского государственного университета Сурна Сарбашева.

Фото - tuvsu.ru
Возможности использования ресурсов Узбекского национального корпуса в создании словарей узбекского языка разного типа были изложены в докладе Нилуфар Абдурахмоновой из Национального университета Узбекистана им. Мирзо Улугбека. От имени большой группы разработчиков технологий машинного перевода в тюркских языках выступил Жамшидбек Мирзахалов из Университета Южной Флориды. Он ознакомил всех с корпусом «Turkic interlingua», применяемым для улучшения машинного перевода на тюркских языках.
Модераторами секций выступили старший научный сотрудник НОЦ «Тюркология» Аржаана Хертек, и доцент кафедры русского языка и литературы Валентина Ондар. Второй день работы конференции был завершен «Круглым столом», во время которого обсуждались актуальные проблемы компьютерной обработки тюркских языков.
Айрат Гатиатуллин, кандидат технических наук, ведущий научный сотрудник Института прикладной семиотики АН Республики Татарстан вынес на обсуждение возможность совместной работы специалистов в области тюркских языков в рамках проектов по созданию единого пространства для совместных лингвистических исследований по тюркским языкам. В частности, по развитию структурно-параметрической функциональной модели тюркских морфем, специальных лингвистических баз данных, описывающих языковые единицы тюркских языков на разных лингвистических уровнях: морфологическом, синтаксическом, семантическом. Предложение встретило живой отклик у всех участников.

Фото - tuvsu.ru
В рамках заключительного дня, 23 сентября, состоялся семинар «Computational Models in Turkic Language and Speech».
Источник: Пресс-служба ТувГУ
Назад к списку